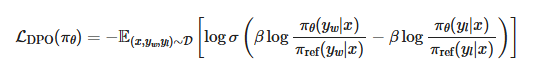- https://arxiv.org/pdf/2305.18290
DPO的核心
DPO核心创新在于将”语言模型暗藏着奖励模型”这一理论洞见转化为实用的训练方法,使得模型对齐过程变得更加简单、高效和稳定。
DPO如何解决RLHF的核心问题
DPO(直接偏好优化)通过以下方式简化和解决RLHF的问题:
- 数学转换:DPO发现了一种巧妙的数学变换,将RLHF两阶段过程转化为单一损失函数
- 无需显式奖励模型:利用最优策略与奖励的数学关系,DPO证明了可以跳过奖励模型训练
- 直接使用偏好数据:DPO直接从成对的偏好数据学习,避免了中间奖励模型
- 隐式KL约束:DPO在损失函数中自然包含了KL散度约束,无需额外处理
- 简化实现:转化为标准监督学习形式,可以使用常规的优化器和训练流程
- 训练稳定性提升:避免了RL训练中的不稳定性问题
- 计算效率更高:无需多次采样和评估,大大降低了计算成本
1.什么是DPO
核心要点
- 偏好排序(PreFerenct Ordering):DPO 的目标是通过优化模型生成的文本与人类期望的文本之间的偏好排序来进行训练。假设有一组文本(例如上边所说已知优质文章和差文章),DPO会根据某些标准(比如文本的流畅性、相关性等)对这些文本进行排序。然后,模型通过学习如何生成更符合这种排序的文本来进行优化。
- 无需奖励模型:与RLHF不同,DPO不需要一个复杂的奖励模型。RLHF中需要通过大量的人工反馈来训练一个奖励模型,而DPO通过直接利用排序数据来优化模型,无需复杂的奖励函数。
- 优化目标:DPO的优化目标是使模型生成的文本尽可能符合给定的偏好排序。例如,如果给定一个文本集合,DPO会根据这些文本的优劣顺序来训练模型,使得模型生成的文本与偏好的顺序更加一致。
2.最优策略的数学形式
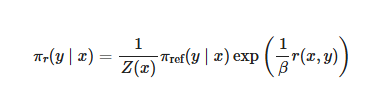

推导到下面
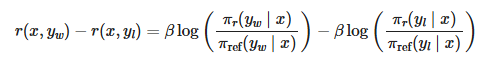
这个公式揭示了一个惊人的发现:奖励函数可以用策略的比值表示。
具体意义:
- 不需要显式奖励模型:我们可以直接从策略比值计算奖励
- 关键简化:在比较两个答案优劣时,常数项β log Z(x)会消除
- 直接优化:可以直接优化策略,而不是先学习奖励模型再优化策略
3. 损失函数
单样本似然函数:
在概率论中,如果事件是独立的,那么它们同时发生的概率等于各自发生概率的乘积。
- 假设数据集中每个偏好样本 $(x, y_w, y_l)$ 都是独立采样的
- 整个数据集被同时观测到的概率,等于二秘阁样本被观测到的概率之积
整个数据集的似然函数:
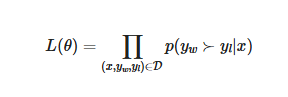
之前推导的偏好概率公式:
$$p\left(y_{w} \succ y_{l} \mid x\right)=\sigma\left(\beta \log \frac{\pi_{\theta}\left(y_{w} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{w} \mid x\right)}-\beta \log \frac{\pi_{\theta}\left(y_{l} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{l} \mid x\right)}\right)$$
将这个表达式代入损失函数,最终的DPO损失函数:
$\mathcal{L}{\mathrm{DPO}}(\pi\theta)=-\mathbb{E}{(x,y_m,y_l)\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi\theta(y_w|x)}{\pi_{\mathrm{ref}}(y_w|x)}-\beta\log\frac{\pi_\theta(y_l|x)}{\pi_{\mathrm{ref}}(y_l|x)}\right)\right]$