单头注意力机制
Q, K, V的理解。
假设Q由如下矩阵组成(不考虑batchsize):
Q[0]:词1:[dim1, dim2, dim3…]
Q[1]:词2:[dim1, dim2, dim3…]
同理K:
K[0]:词1:[dim1, dim2, dim3…]
K[1]:词2:[dim1, dim2, dim3…]
同理V:
V[0]:词1:[dim1, dim2, dim3…]
V[1]:词2:[dim1, dim2, dim3…]
那么Q @ V.T 就是在该词的叉乘和。即计算该词的特征。如果是K的第一行和V的第一列。那么就是计算自己的特征。如果是V的第i列则是计算第一个词和第i个词之间的特征。
Q @ K的结果矩阵:
QK[0]:词1:[词1, 词2, 词3…]
QK[1]:词2:[词1, 词2, 词3…]
此时再 @ V就是对所有词总和一下。QK[0,:] * K[:,0] = 词1*词1+词2*词2…
Softmax计算
直观例子
假设 batch_size=1、num_heads=1、seq_len=3,qk 矩阵如下:
qk = [
[1.0, 0.5, 0.2], # 第1个查询对3个键的分数
[0.3, 1.2, 0.8], # 第2个查询对3个键的分数
[0.7, 0.1, 1.5] # 第3个查询对3个键的分数
]执行 softmax(dim=-1) 后:
softmax_qk = [
[0.50, 0.30, 0.20], # 第1个查询的权重分配
[0.15, 0.50, 0.35], # 第2个查询的权重分配
[0.30, 0.15, 0.55] # 第3个查询的权重分配
]每一行的和为 1,符合注意力权重的定义。
维度解释
torch.softmax官方的解释:
参数
dim(int)– 计算 Softmax 的维度(因此 dim 上每个切片的总和为 1)。
Question:-1不是最后一维吗?在矩阵中最后一维不就是列吗?不是对这一列计算让这一列加和为1吗?
假设有一个矩阵(2D张量):
A = [
[a, b, c], # 第1行
[d, e, f] # 第2行
]最后一维(dim=-1)是“列”:a, b, c 是第一行的3个列元素。确实是对每一行的所有列计算了softmax。
A[0][0]=a, A[0][1]=b, A[0][2]=c.我们一般是想对最后一维softmax,也就是A[0][0-3]计算。那就其实是如题意一样。torch.softmax(A, dim=-1)就行。
代码实现
class SelfAttention(nn.Module):
def __init__(self, hidden_size,):
super().__init__()
self.Q=nn.Linear(hidden_size, hidden_size)
self.K=nn.Linear(hidden_size, hidden_size)
self.V=nn.Linear(hidden_size, hidden_size)
self.linear=nn.Linear(hidden_size, hidden_size)
def forward(self, x, causal_mask=None, pad_mask=None):
bs, hd = x.shape[0], x.shape[2]
q=self.Q(x)
k=self.K(x)
v=self.V(x) # (bs, len, dim)
# (len, dim) @ (dim, len) = (len, len)
qk = q @ k.transpose(-1, -2) / (hd**0.5)
if causal_mask:
qk = qk * causal_mask
if pad_mask:
qk = qk * pad_mask
qk = torch.softmax(qk, dim=-1)
res = qk @ v
res=self.linear(res)
return res
x=torch.rand(2, 192, 64)
# print(x.transpose(-1, -2).shape)
model=SelfAttention(64 )
res=model(x)
res.shape
多头注意力
- 这里要注意计算的时候shape是
(batch_size, nums_head, seq_len, dim)而不是(batch_size, seq_len, nums_head, dim)就行
代码实现
class MultiHeadCrossAttention(nn.Module):
def __init__(self, hidden_size, head_nums):
super().__init__()
self.Q=nn.Linear(hidden_size, hidden_size)
self.K=nn.Linear(hidden_size, hidden_size)
self.V=nn.Linear(hidden_size, hidden_size)
self.linear=nn.Linear(hidden_size, hidden_size)
self.head_nums=head_nums
def forward(self, q, key_value, causal_mask=None, pad_mask=None):
(bs, N, hd) = q.shape
hd/=self.head_nums
q=self.Q(q)
k=self.K(key_value)
v=self.V(key_value) # (bs, len, dim)
# (bs, len, head_nums, dim/head_nums) -> (bs,head_nums,len,dim/head_nums)
q=q.reshape(bs, N, self.head_nums, -1).transpose(1,2)
k=k.reshape(bs, N, self.head_nums, -1).transpose(1,2)
v=v.reshape(bs, N, self.head_nums, -1).transpose(1,2)
# (len, dim) @ (dim, len) = (len, len)
qk = q @ k.transpose(-1, -2) / (hd**0.5)
if causal_mask:
qk = qk * causal_mask
if pad_mask:
qk = qk * pad_mask
qk = torch.softmax(qk, dim=-1)
res = qk @ v #(bs,head_nums,len,dim/head_nums)
res = res.transpose(1,2).reshape(bs, N, -1)
res=self.linear(res)
return res
class MultiHeadSelfAttention(nn.Module):
def __init__(self, hidden_size, head_nums):
super().__init__()
self.head_nums=head_nums
self.hidden_size=hidden_size
self.Q=nn.Linear(hidden_size, hidden_size)
self.K=nn.Linear(hidden_size, hidden_size)
self.V=nn.Linear(hidden_size, hidden_size)
self.linear=nn.Linear(hidden_size, hidden_size)
def forward(self, x, causal_mask=None, pad_mask=None):
(bs, N, hd) = x.shape
q=self.Q(x)
k=self.K(x)
v=self.V(x) # (bs, len, dim)
hd/=self.head_nums
q=q.reshape(bs, N, self.head_nums, -1).transpose(1,2)
k=k.reshape(bs, N, self.head_nums, -1).transpose(1,2)
v=v.reshape(bs, N, self.head_nums, -1).transpose(1,2)
# (len, dim) @ (dim, len) = (len, len)
qk = q @ k.transpose(-1, -2) / (hd**0.5)
if causal_mask:
qk = qk * causal_mask
if pad_mask:
qk = qk * pad_mask
qk = torch.softmax(qk, dim=-1)
res = qk @ v
res = res.transpose(1,2).reshape(bs, N, -1)
res=self.linear(res)
return res
if __name__=='__main__':
'''
multi-head attention
'''
q=torch.rand(2, 192, 64)
encoder_output=torch.rand(2, 192, 64)
# print(x.transpose(-1, -2).shape)
model=MultiHeadCrossAttention(64, 8)
res=model(q, encoder_output)
print(res.shape)
'''
self-attention
'''
x=torch.rand(2, 192, 64)
# print(x.transpose(-1, -2).shape)
model=MultiHeadSelfAttention(64, 8)
res=model(x)
print(res.shape)
Tranformer Encoder
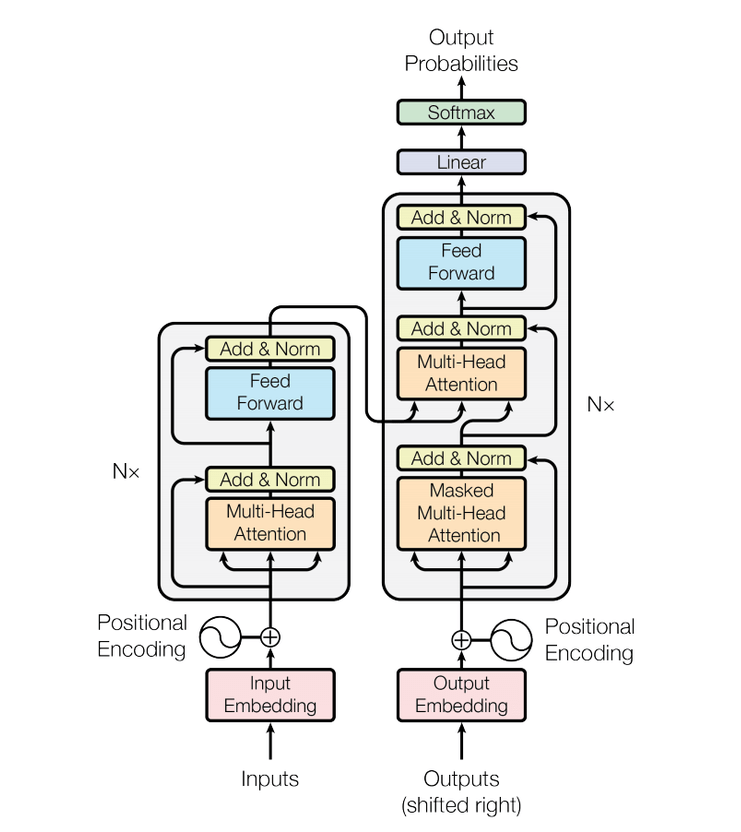
Position Embedding & Token Embedding
传统位置编码:
$$ \mathbf{PE}{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d{\text{model}}}}}\right) $$
其中,$- pos$ 表示位置索引。 $- i$ 表示维度索引。 $- d_model$ 表示嵌入维度的大小。
from torch import nn
import torch
import math
from transformers import AutoTokenizer, AutoModelForMaskedLM
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size) # 嵌入层
def forward(self, x):
# x 形状: (batch_size, seq_len)
embedded = self.embedding(x) # 嵌入后的形状: (batch_size, seq_len, hidden_size)
return embedded
class PositionalEmbedding(nn.Module):
def __init__(self, max_len, hidden_size):
super().__init__()
self.hidden_size = hidden_size
# 创建位置编码表,大小为 (max_len, hidden_size)
# position: (max_len, 1),表示序列中的位置索引,例如 [[0.], [1.], [2.], ...]
position = torch.arange(0, max_len).unsqueeze(1).float()
# div_term: (hidden_size / 2),用于计算位置编码的分母
div_term = torch.exp(torch.arange(0, hidden_size, 2).float() * (-math.log(10000.0) / hidden_size))
# 初始化位置编码矩阵 pe 为零矩阵,大小为 (max_len, hidden_size)
pe = torch.zeros(max_len, hidden_size)
# 计算位置编码矩阵,广播机制将 dive_term 扩展为 (1, hidden_size )
# 偶数索引列使用 sin 函数
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数索引列使用 cos 函数
pe[:, 1::2] = torch.cos(position * div_term)
# 将位置编码矩阵注册为 buffer,模型训练时不会更新它
self.register_buffer('pe', pe)
def forward(self, x):
# x 的形状: (batch_size, seq_len, hidden_size)
seq_len = x.size(1)
# 将位置编码加到输入张量上
# self.pe[:seq_len, :] 的形状为 (seq_len, hidden_size)
# unsqueeze(0) 使其形状变为 (1, seq_len, hidden_size),便于与输入张量相加
x = x + self.pe[:seq_len, :].unsqueeze(0)
# 返回加上位置编码后的张量
return x
if __name__ == "__main__":
# 1) 取一个真正大模型的词表(BERT base)
# Load model directly
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
# model = AutoModelForMaskedLM.from_pretrained("google-bert/bert-base-uncased")
vocab_size = tokenizer.vocab_size # 30522
hidden_size = 768 # 跟 bert-base-uncased 一致
# 2) 实例化自定义的 TokenEmbedding
model = TokenEmbedding(vocab_size, hidden_size)
# 3) 准备若干句子
sentences = [
"Transformers are amazing!",
"Let's test our token embedding layer."
]
# 4) 使用 tokenizer 转成 token ids;同时统一 sequence length(padding)
encoded = tokenizer(
sentences,
padding=True,
truncation=True,
return_tensors="pt"
)
input_ids = encoded["input_ids"] # shape: (batch_size, seq_len)
print("Token IDs:\n", input_ids)
print("Shape:", input_ids.shape)
# 5) 喂进嵌入层
with torch.no_grad():
embedded = model(input_ids) # (batch_size, seq_len, hidden_size)
print("Embedded Tensor Shape:", embedded.shape, '\n')
embedding_table = model.embedding.weight # (vocab_size, hidden_size)
# -------- 从 embedded 反推出 token id --------------
# 把 (batch, seq_len, hidden) 拉平成 (batch*seq_len, hidden)
flat_emb = embedded.view(-1, hidden_size) # (B*S, H)
# 点积得到相似度,越大越相似
sim = torch.matmul(flat_emb, embedding_table.t()) # (B*S, V)
print('embedding_table.shape:', embedding_table.shape)
# 对 vocab 维度取 argmax 得到最相似的 token id
pred_ids = torch.argmax(sim, dim=-1) # (B*S, )
# reshape 回原来的 (batch, seq_len)
pred_ids = pred_ids.view(embedded.size(0), embedded.size(1))
print("\nRecovered ids:")
print(pred_ids)
# -------- 2. 解码成字符串 -----------------------------
decoded_text = tokenizer.batch_decode(
pred_ids,
skip_special_tokens=False, # 为了对照,先不去掉 [PAD]/[CLS]/[SEP]
clean_up_tokenization_spaces=True
)
print('original text')
print(sentences)
print("\nDecoded text:")
for i, sent in enumerate(decoded_text):
print(f"{i}: {sent}")
pos_emb_model = PositionalEmbedding(vocab_size, hidden_size)
pos_emb_embedded = pos_emb_model(embedded)
print('\npos_emb_embedded.shape:', pos_emb_embedded.shape)
Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self, hidden_size, num_heads, ff_size, dropout_prob=0.1):
super().__init__()
self.multi_head_attention = MultiHeadSelfAttention(hidden_size, num_heads) # 多头注意力层
self.dropout1 = nn.Dropout(dropout_prob) # Dropout 层
self.layer_norm1 = nn.LayerNorm(hidden_size) # LayerNorm 层
self.feed_forward = nn.Sequential(
nn.Linear(hidden_size, ff_size), # 前馈层1
nn.ReLU(), # 激活函数
nn.Linear(ff_size, hidden_size) # 前馈层2
)
self.dropout2 = nn.Dropout(dropout_prob) # Dropout 层
self.layer_norm2 = nn.LayerNorm(hidden_size) # LayerNorm 层
def forward(self, x, attention_mask=None):
# 多头注意力子层
attn_output = self.multi_head_attention(x, attention_mask) # (batch_size, seq_len, hidden_size)
attn_output = self.dropout1(attn_output) # Dropout
out1 = self.layer_norm1(x + attn_output) # 残差连接 + LayerNorm
# 前馈神经网络子层
ff_output = self.feed_forward(out1) # (batch_size, seq_len, hidden_size)
ff_output = self.dropout2(ff_output) # Dropout
out2 = self.layer_norm2(out1 + ff_output) # 残差连接 + LayerNorm
return out2
x=torch.rand(2, 192, 64)
model=EncoderLayer(64, 8, 32)
model(x).shapeTransformer Decoder
Transformer的Decoder层与Encoder大体类似,除了包含多头自注意力机制和前馈神经网络,还增加了一个用于编码器-解码器注意力机制的多头注意力子层。这使得 Decoder 层能够同时关注当前输出序列的上下文信息和输入序列的编码信息。
CrossAttention
import torch.nn as nn
import torch
class MultiHeadCrossAttention(nn.Module):
def __init__(self, hidden_size, head_nums):
super().__init__()
self.Q=nn.Linear(hidden_size, hidden_size)
self.K=nn.Linear(hidden_size, hidden_size)
self.V=nn.Linear(hidden_size, hidden_size)
self.linear=nn.Linear(hidden_size, hidden_size)
self.head_nums=head_nums
def forward(self, q, key_value, causal_mask=None, pad_mask=None):
(bs, N, hd) = q.shape
hd/=self.head_nums
q=self.Q(q)
k=self.K(key_value)
v=self.V(key_value) # (bs, len, dim)
# (bs, len, head_nums, dim/head_nums) -> (bs,head_nums,len,dim/head_nums)
q=q.reshape(bs, N, self.head_nums, -1).transpose(1,2)
k=q.reshape(bs, N, self.head_nums, -1).transpose(1,2)
v=q.reshape(bs, N, self.head_nums, -1).transpose(1,2)
# (len, dim) @ (dim, len) = (len, len)
qk = q @ k.transpose(-1, -2) / (hd**0.5)
if causal_mask:
qk = qk * causal_mask
if pad_mask:
qk = qk * pad_mask
qk = torch.softmax(qk, dim=-1)
res = qk @ v #(bs,head_nums,len,dim/head_nums)
res = res.transpose(1,2).reshape(bs, N, -1)
res=self.linear(res)
return res
q=torch.rand(2, 192, 64)
encoder_output=torch.rand(2, 192, 64)
# print(x.transpose(-1, -2).shape)
model=MultiHeadCrossAttention(64, 8)
res=model(q, encoder_output)
res.shape
Decoder Layer
class DecoderLayer(nn.Module):
def __init__(self, hidden_size, num_heads, ff_size, dropout_prob=0.1):
super().__init__()
self.multi_head_attention = MultiHeadSelfAttention(hidden_size, num_heads) # 多头注意力层
self.dropout1 = nn.Dropout(dropout_prob) # Dropout 层
self.layer_norm1 = nn.LayerNorm(hidden_size) # LayerNorm 层
self.multi_head_attention2 = MultiHeadCrossAttention(hidden_size, num_heads) # 多头注意力层
self.dropout2 = nn.Dropout(dropout_prob) # Dropout 层
self.layer_norm2 = nn.LayerNorm(hidden_size) # LayerNorm 层
self.feed_forward = nn.Sequential(
nn.Linear(hidden_size, ff_size), # 前馈层1
nn.ReLU(), # 激活函数
nn.Linear(ff_size, hidden_size) # 前馈层2
)
self.dropout3 = nn.Dropout(dropout_prob) # Dropout 层
self.layer_norm3 = nn.LayerNorm(hidden_size) # LayerNorm 层
def forward(self, x, encoder_output, attention_mask=None):
# 多头注意力子层
attn_output = self.multi_head_attention(x, attention_mask) # (batch_size, seq_len, hidden_size)
attn_output = self.dropout1(attn_output) # Dropout
out1 = self.layer_norm1(x + attn_output) # 残差连接 + LayerNorm
cross_out=self.multi_head_attention2(out1, encoder_output)
cross_attn_output = self.dropout1(cross_out) # Dropout
out2 = self.layer_norm2(out1 + cross_attn_output) # 残差连接 + LayerNorm
# 前馈神经网络子层
ff_output = self.feed_forward(out2) # (batch_size, seq_len, hidden_size)
ff_output = self.dropout2(ff_output) # Dropout
out3 = self.layer_norm3(out2 + ff_output) # 残差连接 + LayerNorm
return out2
x=torch.rand(2, 192, 64)
encoder_output=torch.rand(2, 192, 64)
model=DecoderLayer(64, 8, 32)
model(x, encoder_output).shape